作物表型组学研究中心合作建成植物图像及相关性状开放归档库
发布时间:2023.11.06
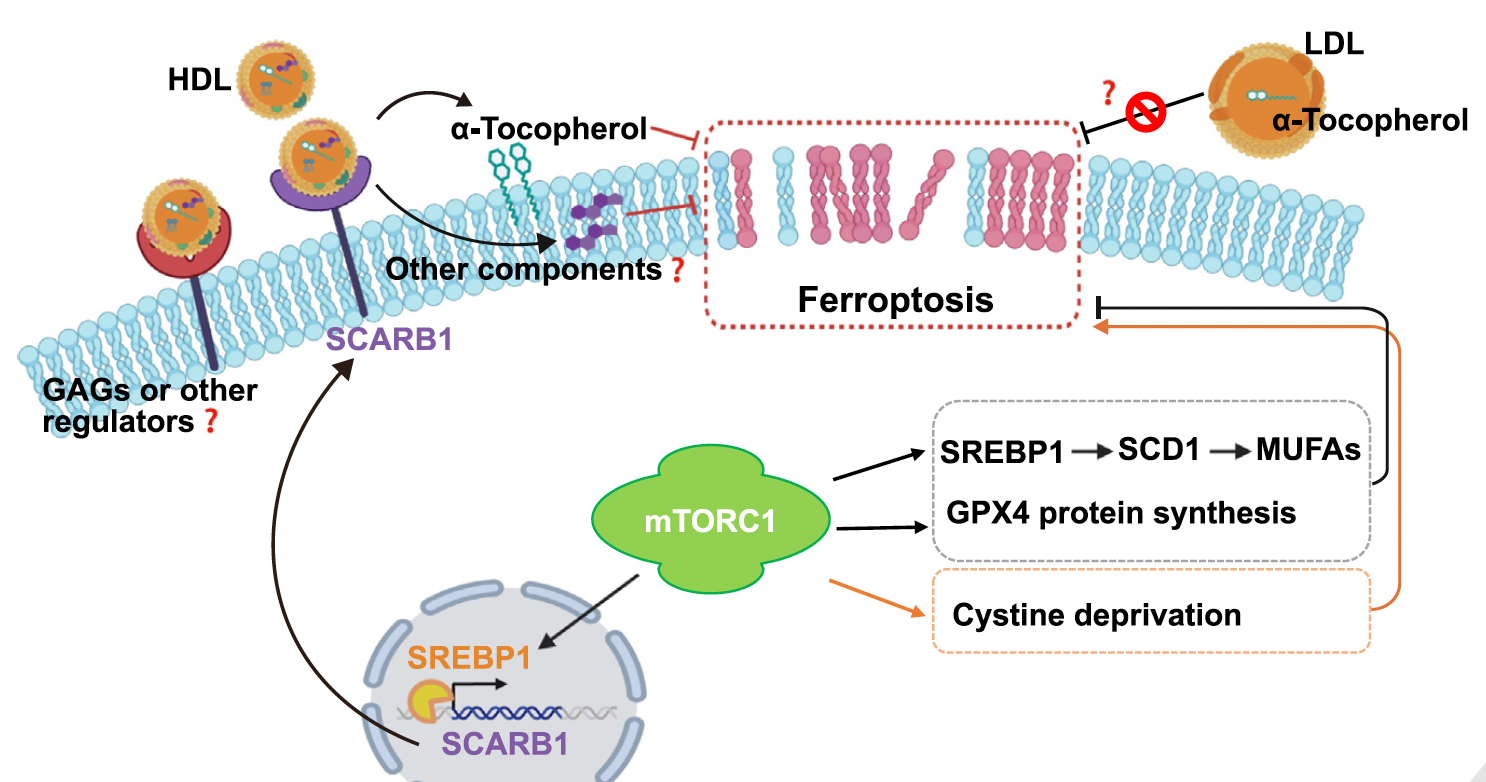
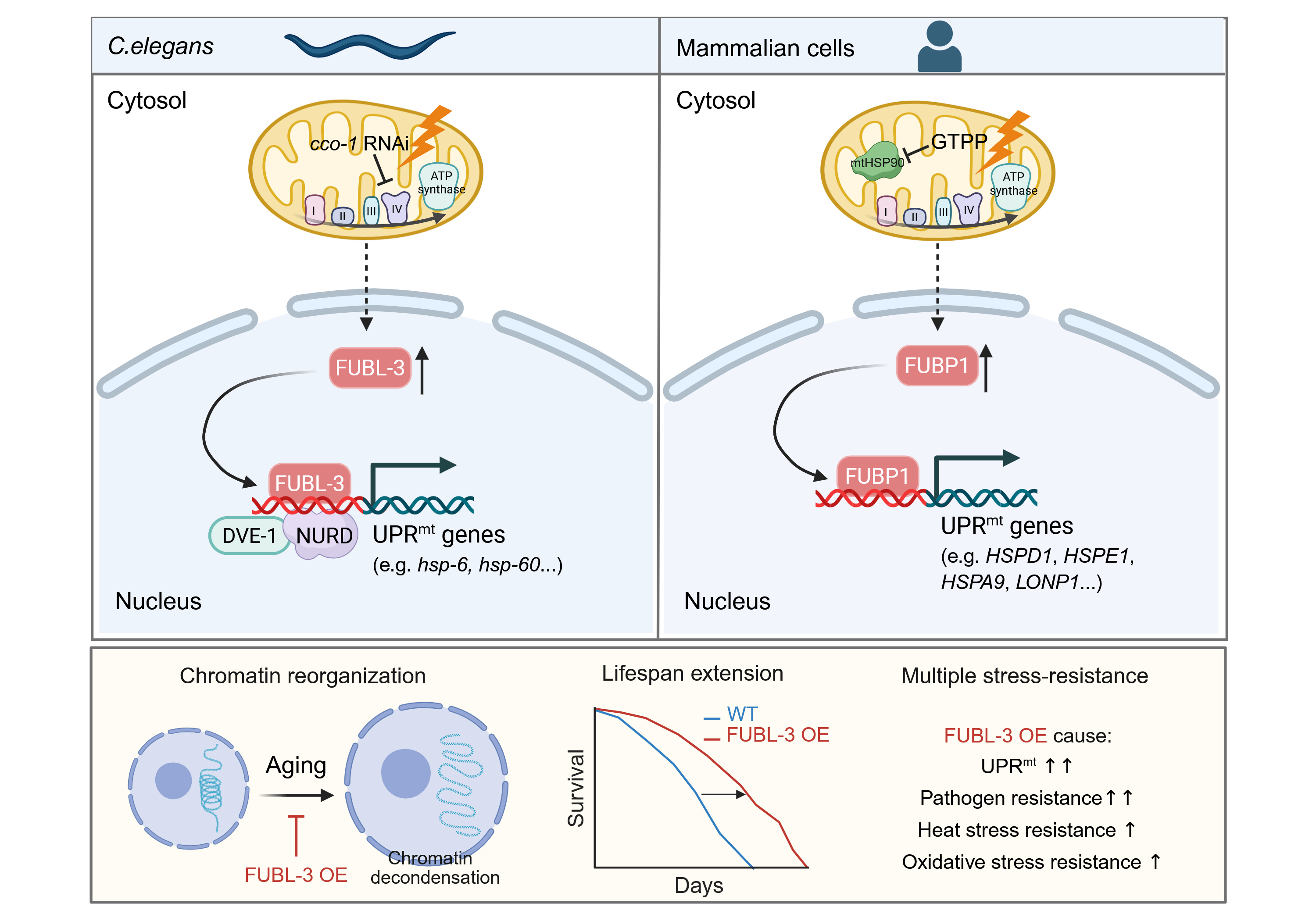
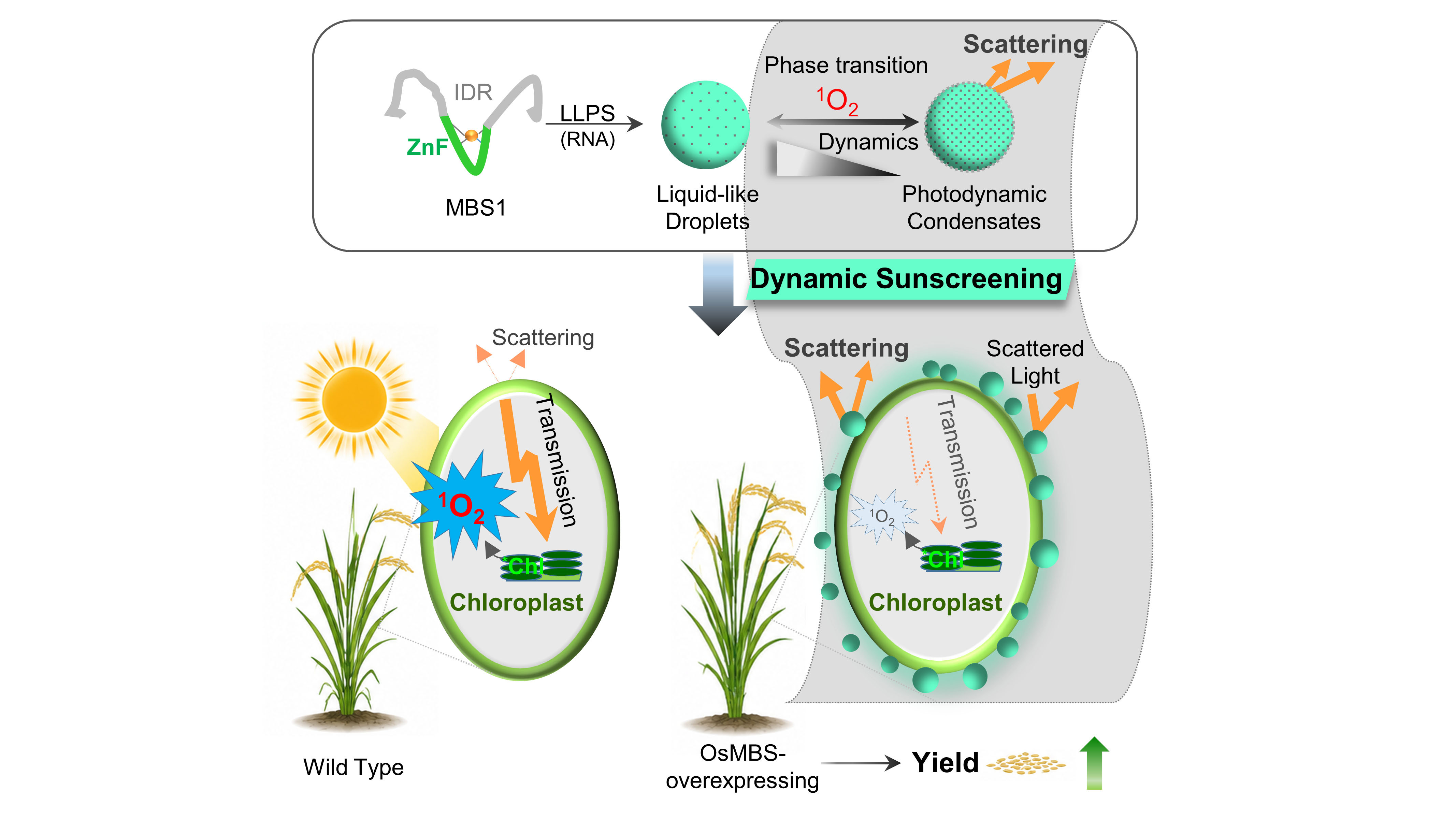
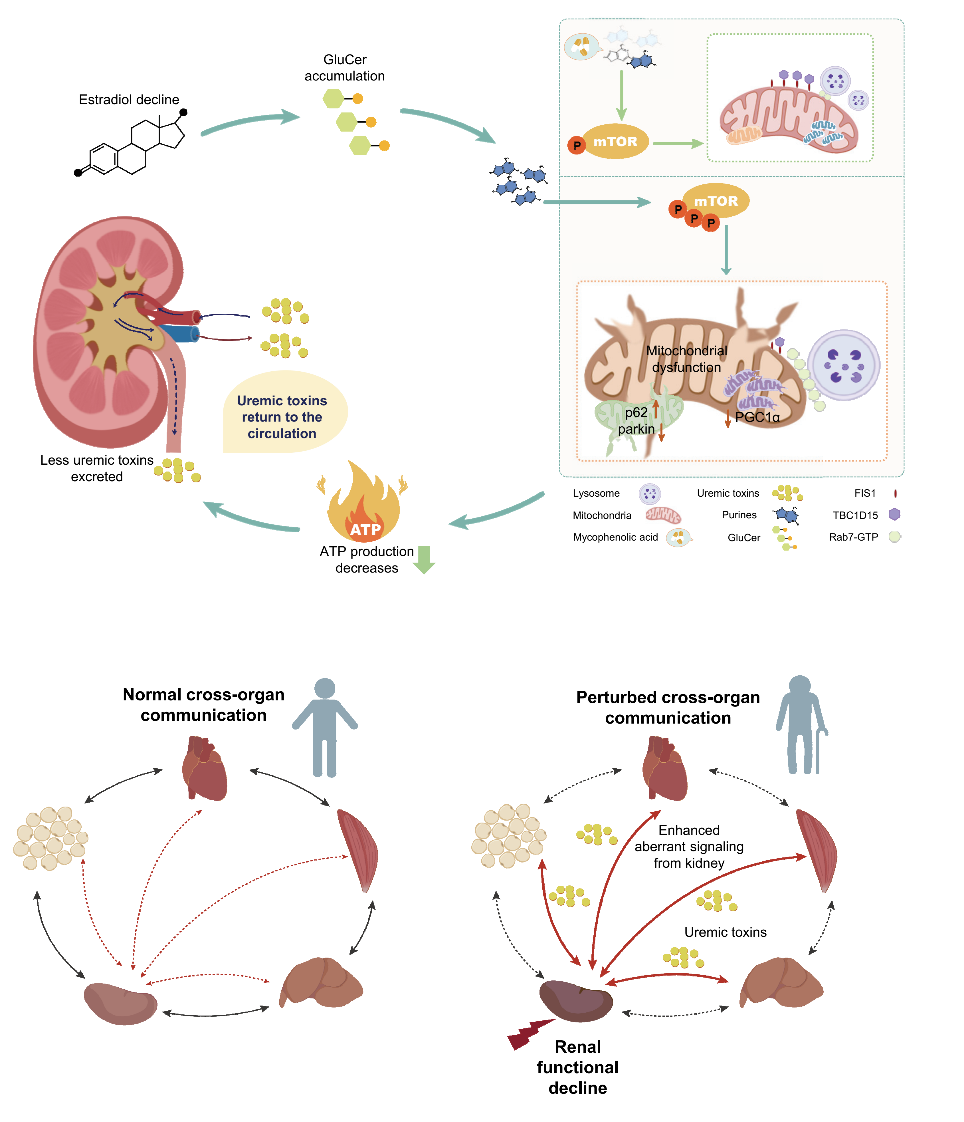
植物图像包含非常丰富的信息,可以反映植物的颜色、形态、生长和健康状态等关键表型特征。高通量植物表型采集技术在植物表型组学研究中广泛应用,产生了大量的图像和基于图像的性状数据,这些数据是种质筛选、植物病虫害鉴定、农艺性状挖掘等应用的重要资源。构建植物图像及相关性状数据管理平台,提供植物图像及相关性状数据的集中管理、分析和共享,不仅有利于数据的查询、访问、互操作和重复利用,还有助于图像的元信息与表型数据的标准化,是当前智慧农业驱动下植物表型组学数据应用的重要支撑平台。
近日,中国科学院遗传与发育生物学研究所作物表型组学研究中心与中国科学院北京基因组研究所(国家生物信息中心)合作开发的植物图像及相关性状开放归档库(OPIA)正式上线,为国内外科研人员提供植物图像及相关性状数据递交与共享的公共服务。该研究成果以“OPIA: an open archive of plant images and related phenotypic traits”为题在国际学术期刊Nucleic Acid Research 在线发表。
OPIA采用标准化人工审编流程整合了56个高质量的植物图像数据集,涵盖11个物种、6种组织类型,总计566,225张图像、2,417,186个注释实例。值得关注的是,OPIA基于18,644张单株RGB图像,整合了93个水稻和105个小麦品系的56个图像性状,并基于植物性状本体对这些基于图像的性状进行了进一步的注释和GWAS Atlas记录关联。此外,OPIA中的每个图像数据集被计算一个评价分数,该分数综合考虑了图像样本数量、图像质量、图像样本的丰富度、图像标签类别平衡性等因素,为用户提供了直观的数据质量评价。另外,OPIA还提供了图像预处理和智能预测工具,辅助进行批量化图像数据增强及预处理。
作为植物图像及相关性状的综合资源归档库,OPIA在整合来自不同采集平台、组织类型和表型性状的植物表型组学数据分析方面发挥着重要作用。通过对来自不同传感器类型的图像样本及相应标签数据的运用,促进研究人员进一步提高智能预测方法的精度,揭示植物生长的动态规律,进而推动全球植物表型组学领域的创新和发展。
北京基因组所(国家生物信息中心)博士研究生曹永荣、工程师田东梅为本文共同第一作者,北京基因组所(国家生物信息中心)宋述慧研究员、章张研究员和中国科学院遗传与发育生物学研究所高级工程师胡伟娟博士为共同通讯作者。该研究得到了科技创新2030-重大项目、国家自然科学基金、中国科学院战略性先导科技专项、中国科学院青促会等项目资助。
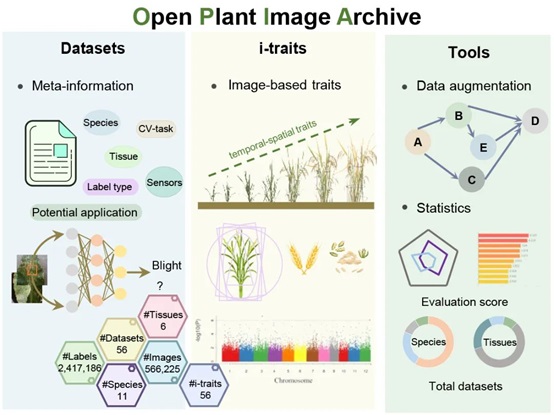
图:OPIA功能概览